Hi Daniel,
I was thinking about it due to very less number of indexing. Thanks for your suggestion.
Welcome to the Q&A Forum
Browse the forum for helpful insights and fresh discussions about all things SEO.
Hi Daniel,
I was thinking about it due to very less number of indexing. Thanks for your suggestion.
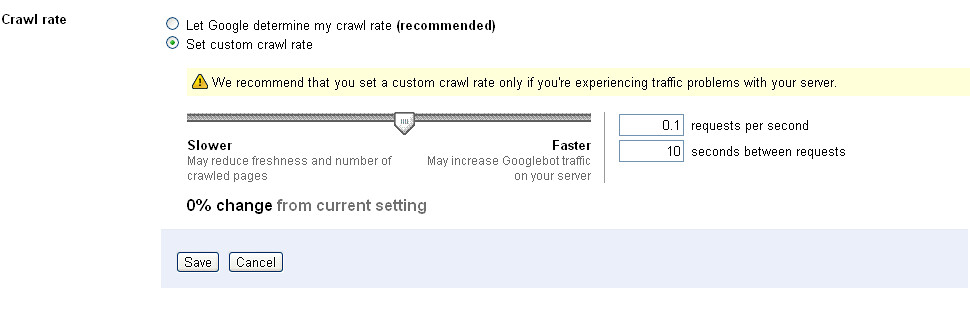
This is really silly question to set custom crawl rate in Google webmaster tools. Any one can find out that section under setting tab. But, I have confusion to decide number for request per second and second between requests text field.
I want to set custom crawl rate for my eCommerce website.
I checked my Google webmaster tools and find out as attachment. So, Can I use this facility to improve my crawling?
Hi, Liam
I come back on this question after long time. Because, I am still surviving with crawling issue. Google is not crawling my website after implement all checklists.
Today, I read one blog post about to increase Google crawl rate.
Blog suggesting to set custom crawl rate with help of Google webmaster tools. So, Does it really matter to improve crawling?
What is important and helpful ... natural crawling by Google or embarrassing crawling by Google?
I wouldn't recommend spending money or much time on a directory inclusion/link placement for a page that is not in the primary index and has at least a PageRank of 1 (the page itself - not the domain)
Thanks for your great list and sharing of experience. But, I have one question about above statement. Does it really matter?
Recently, I saw following Webinar on SEOmoz.
Both Webinar are excellent and get too many new things about link building. They recommend to do directory with specific manner and spending less time over there. They are focusing to do something real to gather natural links. What's something real in link building.
I can 100% agree with quality and paid directory where we can add our website with certain budget management.
In social culture, natural link environment... Does it rally matter to focus on directory? What you think about it? If you can give me more idea so it will help me more to understand about it. Thanks again for your answer.
I checked your tool and really helpful. But, I have one question for this tool.
Yesterday, I have submitted one comment on blog post of Inspired Mag. My comment is on 2nd place. It's with nofollow attribute so I know that, it will not pass any page rank to my website.
Now, I checked that blog post URL with tool and give me following statistic.
Total Links found: 1624
Unique Links found: 1307
Questionable Links found: 3
Pages scanned: 40
So, It's only for specific web page? If yes so what about entire website? I am not opposing you but have mind bubble to be more clear about it. Thanks again for your insightful answer.
I want to know about process, method or tool which can help me to define quality of external website during link building.
We are searching too many questions and topics on Google to resolve daily mind bubbles which land us on different website with different subject.
I found that, I was able to drop my website URL over there but confuse about quality of website.
I am selling Football and create external link from baby care website. So, will it make sense? My concern is that, Can we create external links from different subject website or specific to subject oriented website?
Is there any specific method which help me to understand more about external website and help me to take decision about link building?
I got it.... I am going to implement as previous one. Thanks for your prompt reply.
Can I use Remove URL facility from Google webmaster tools?
@Gianluca Fiorelli
I have added following Meta in all duplicate products [2 to 11] exclude primary product [1].
I have marked this question as answered but raise one question after observe source code of all product pages. I have implemented following canonical on all duplicate product pages pointing to unique product.
So, now is it require on duplicate pages? Can I remove it from entire website? Because, duplication will not occur due to prevention of indexing for all duplicate products.
Note: I am still surviving from crawling issue. My crawling is still very slow and only 113 pages were indexed by Google.
I have added Options -Indexes for images folder in htaccess file.
But, I still able to find out images folder in Google indexing.
Can I check? Is it working properly or not? I don't want to index or display images folder in web search any more.
I was checking URL parameters section over Google webmaster tools. Google have monitored following parameters and exclude it from crawling.
utm_campaign
utm_medium
utm_source
I have built URLs with following tool to track visits from vertical search engine like Google shopping and other comparison shopping engines.
http://www.google.com/support/analytics/bin/answer.py?answer=55578
So, I am quite confuse to see over my data.
Will Google consider external URLs which are available with above parameters or require to consist on live website?
Note: I am asking for my eCommerce website. http://www.lampslightingandmore.com/
I am targeting my website in US so need to get high organic ranking in US web search.
One of my competitor is restricting website access to specific IP address or Geo location.
I have checked multiple categories to know more. What's going on with this restriction and why they make it happen?
One of SEO forum is also restricting website access to specific location.
I can understand that, it may help them to stop thread spamming with unnecessary Sign Up or Q & A.
But, why Lamps Plus have set this? Is there any specific reason?
Can I improve my organic ranking?
Restriction may help me to save and maintain user statistic in terms of bounce rate, average page views per visit, etc...
Even if you don’t want a page to rank,
Page rank is ranking factor? I don't think so... I am not opposing you but in my category there are many websites which are performing well with low page rank. And, high page rank website is still at bottom.
Have you any idea about it?
Are you talking like this?
I have fix URL structure for all products and manipulate that product in multiple categories.
There will no change in URL structure.
Today, I was reading about NoFollow on Wikipedia. Following statement is over my head and not able to understand with proper manner.
"Google states that their engine takes "nofollow" literally and does not "follow" the link at all. However, experiments conducted by SEOs show conflicting results. These studies reveal that Google does follow the link, but does not index the linked-to page, unless it was in Google's index already for other reasons (such as other, non-nofollow links that point to the page)."
It's all about indexing and ranking for specific keywords for hyperlink text during external links. I aware about that section. It may not generate in relevant result during any keyword on Google web search.
But, what about internal links? I have defined rel="nofollow" attribute on too many internal links.
I have archive blog post of Randfish with same subject. I read following question over there.
Q. Does Google recommend the use of nofollow internally as a positive method for controlling the flow of internal link love? [In 2007]
A: Yes – webmasters can feel free to use nofollow internally to help tell Googlebot which pages they want to receive link juice from other pages
_
(Matt's precise words were: The nofollow attribute is just a mechanism that gives webmasters the ability to modify PageRank flow at link-level granularity. Plenty of other mechanisms would also work (e.g. a link through a page that is robot.txt'ed out), but nofollow on individual links is simpler for some folks to use. There's no stigma to using nofollow, even on your own internal links; for Google, nofollow'ed links are dropped out of our link graph; we don't even use such links for discovery. By the way, the nofollow meta tag does that same thing, but at a page level.)
Matt has given excellent answer on following question. [In 2011]
Q: Should internal links use rel="nofollow"?
A:Matt said:
"I don't know how to make it more concrete than that."
I use nofollow for each internal link that points to an internal page that has the meta name="robots" content="noindex" tag. Why should I waste Googlebot's ressources and those of my server if in the end the target must not be indexed? As far as I can say and since years, this does not cause any problems at all.
For internal page anchors (links with the hash mark in front like "#top", the answer is "no", of course.
I am still using nofollow attributes on my website.
So, what is current trend? Will it require to use nofollow attribute for internal pages?
You are 100% right. I am not able to see significant changes in crawling after 4 days of implementation. I am thinking to add meta for robots with noindex, nofollow specification on all duplicate product page.
Google will crawl and index only primary product. [That's unique one.] What you think about it? Will it work for me or not?
No, I don't want to index duplicate pages. And, not able to define unique attributes on all duplicate pages. Can you suggest me any alternative?
I read Google webmaster centeral's blog post and help article about rel="canonical" which was compiled by Matt.
http://googlewebmastercentral.blogspot.com/2009/02/specify-your-canonical.html
http://www.google.com/support/webmasters/bin/answer.py?answer=139394
I am working on eCommerce website and found too many duplicate pages with same product as follow.
1. www.lampslightingandmore.com/50_62_10133/java-bronze-floor-lamp-with-walnut-shade.html
2. www.lampslightingandmore.com/48_10133/java-bronze-floor-lamp-with-walnut-shade.html
3. www.lampslightingandmore.com/48_55_10133/java-bronze-floor-lamp-with-walnut-shade.html
4. www.lampslightingandmore.com/48_57_10133/java-bronze-floor-lamp-with-walnut-shade.html
5. www.lampslightingandmore.com/50_10133/java-bronze-floor-lamp-with-walnut-shade.html
6. www.lampslightingandmore.com/50_56_10133/java-bronze-floor-lamp-with-walnut-shade.html
7. www.lampslightingandmore.com/50_63_10133/java-bronze-floor-lamp-with-walnut-shade.html
8. www.lampslightingandmore.com/63_10133/java-bronze-floor-lamp-with-walnut-shade.html
9. www.lampslightingandmore.com/68_10133/java-bronze-floor-lamp-with-walnut-shade.html
10. www.lampslightingandmore.com/68_58_10133/java-bronze-floor-lamp-with-walnut-shade.html
11. www.lampslightingandmore.com/68_59_10133/java-bronze-floor-lamp-with-walnut-shade.html
I have consider 1st product as a primary product and set following rel canonical tag on remaining products. Primary product also contain following rel canonical tag.
This was my experience to set canonical tag. But, I am not able to see any improvement on crawling. I was in that assumption due to duplication Google did not crawled my pages. But, Now what is problem with it? How can I fix it and specify proper canonical link element for better crawling?
Note: I am working to compile unique content on each product pages and make it live very soon.
I am going to add following code to my htaccess page.
Options -Indexes
Will it work for me or not?
{kind=link}